
At OPSWAT, we value innovation, creativity, and continuous improvement when developing advanced solutions to protect critical infrastructure and organizations from cyberthreats. These values inspired us to create the OPSWAT MetaDefender Threat Intelligence, which enables us to better understand and detect evolving cyberthreats to detect and identify similar files.
As malware variants become increasingly sophisticated and evasive, traditional signature-based antivirus solutions are insufficient. To address this challenge, OPSWAT's cybersecurity experts developed an elegant solution that leverages cutting-edge static analysis technology and machine learning to identify similarities shared between files. This approach provides an efficient means of mitigating cybersecurity risks and preventing potential attacks.
Creating the MetaDefender Threat Intelligence gave us an opportunity to tackle a difficult, urgent problem. We were able to develop effective cybersecurity solutions that provide organizations with the information they need to anticipate and prepare for emerging threats. This aligns with our culture of innovation and our commitment to delivering the best possible protection for our customers.

The Data
To perform similarity searches, files undergo a rigorous scanning process using the MetaDefender Aether static and file emulation technologies. This advanced technology extracts the most relevant and useful information from a given file.
Our expert malware analysts have determined the most effective features for calculating the similarities between two files. These features are carefully selected based on their ability to provide accurate and relevant results, and they are continuously updated to stay current with the latest malware trends and techniques.
Some features are:
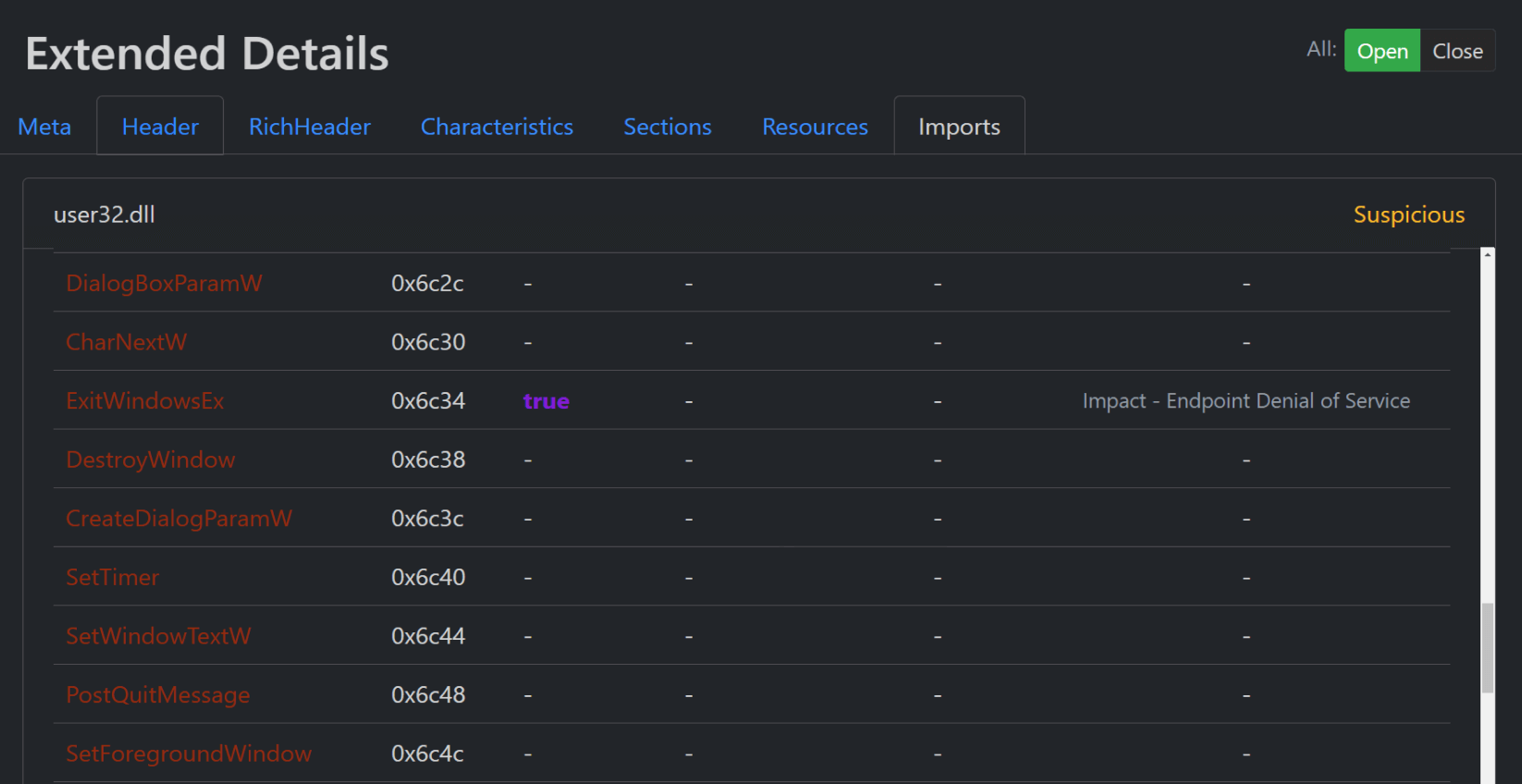
- Binary metadata (file size, entropy, architecture, file characteristic, and many others)
- Imports
- Resources
- Sections
- Signals
- And more
Note: When searching for similarities between files, it is important to use signals generated by Filescan and not to rely solely on the final verdict (Malicious, Informational etc.) of a file. This approach helps to avoid any potential biases that may arise during the similarity search process.

Process
The Similarity Search process involves extracting and transforming these features from Portable Executable (PE) files into vector embeddings. Vector embeddings represent data as points in n-dimensional space, allowing similar data points to cluster together, creating a file fingerprint. The number of dimensions is decided by each section while reducing the dimensionality.
The solution then uses multiple, modified distance calculations between these vectors to find the most similar files, enabling us to answer the question, “how similar is this file to another one?” The architecture and algorithm use indexing methods that ensure fast processing even when searching through millions of files. The algorithmic analysis of these fields enables the solution to accurately identify and isolate similar files and threats.
In addition to advanced technology, Similarity Search provides a customizable interface that allows users to filter their search parameters. This feature offers greater flexibility and ensures that users receive the most accurate and relevant results for their specific needs.
Filters:
- Tags
- Verdict
- Similarity threshold
The Pipeline
The pipeline process involves taking a new input PE file, such as an executable, and subjecting it to machine learning models that generate vector embeddings based on pre-selected features. These vectors are then embedded in a vector space, which can have any number of dimensions.

We use various distance metrics to calculate the similarity between vectors and features, which helps us determine the closest point to a given input PE file.

Similarity Score
It is worth noting that similarity scores are not absolute and may be somewhat subjective. There is no universally accepted formula or standard for determining the degree of similarity between files since this can vary depending on the context and specific use case. So, it’s important to interpret similarity scores with caution and consider the methodology used to calculate them. Similarity search uses weights to calculate an accurate similarity score.
MetaDefender Aether’s Results
The Filescan result provides comprehensive information about the file used for similarity search. However, it is important to thoroughly analyze this information to fully understand the file’s characteristics and properties. The UI displays various properties of a file scan and generates a detailed report of its features.
To access the similarity search feature, navigate to the left-hand side of the user interface. By default, the similarity search feature is automatically initiated with preset, default parameters. Moreover, users are provided with multiple filtering options to help users customize their search and obtain optimal results based on their specified requirements.
Filters:
- Tags: These are dynamic labels assigned to files based on their attributes. When using the similarity search feature, tags can be used to label files with specific characteristics, such as peexe or shell32.dll. Tags help with targeted and efficient searches, enabling users to quickly find files that meet their specific needs.
- Verdict: The Filescan verdict provides the result of a scan conducted on the file, indicating whether the file is clean, malicious, or potentially harmful in some way. By using the Filescan verdict as a filter, users can refine their search results to exclude files flagged as malicious or suspicious.
- Similarity Threshold: This is a configurable parameter that determines the minimum level of similarity needed for files to be included in the search results. By adjusting this threshold, users can customize their search results to meet their specific needs. For example, they can find files that are closely related or those that have a more tenuous connection. This filter is useful for users who need to balance precision with a broad and comprehensive search.
Tabs
In the similarity search feature, users are presented with default filtering options in the form of tabs. These tabs enable users to filter results based on the most similar files, the most recent files, and files that have been flagged with a malicious verdict. These pre-filtering options are designed to enhance the efficiency and precision of the search experience for users.

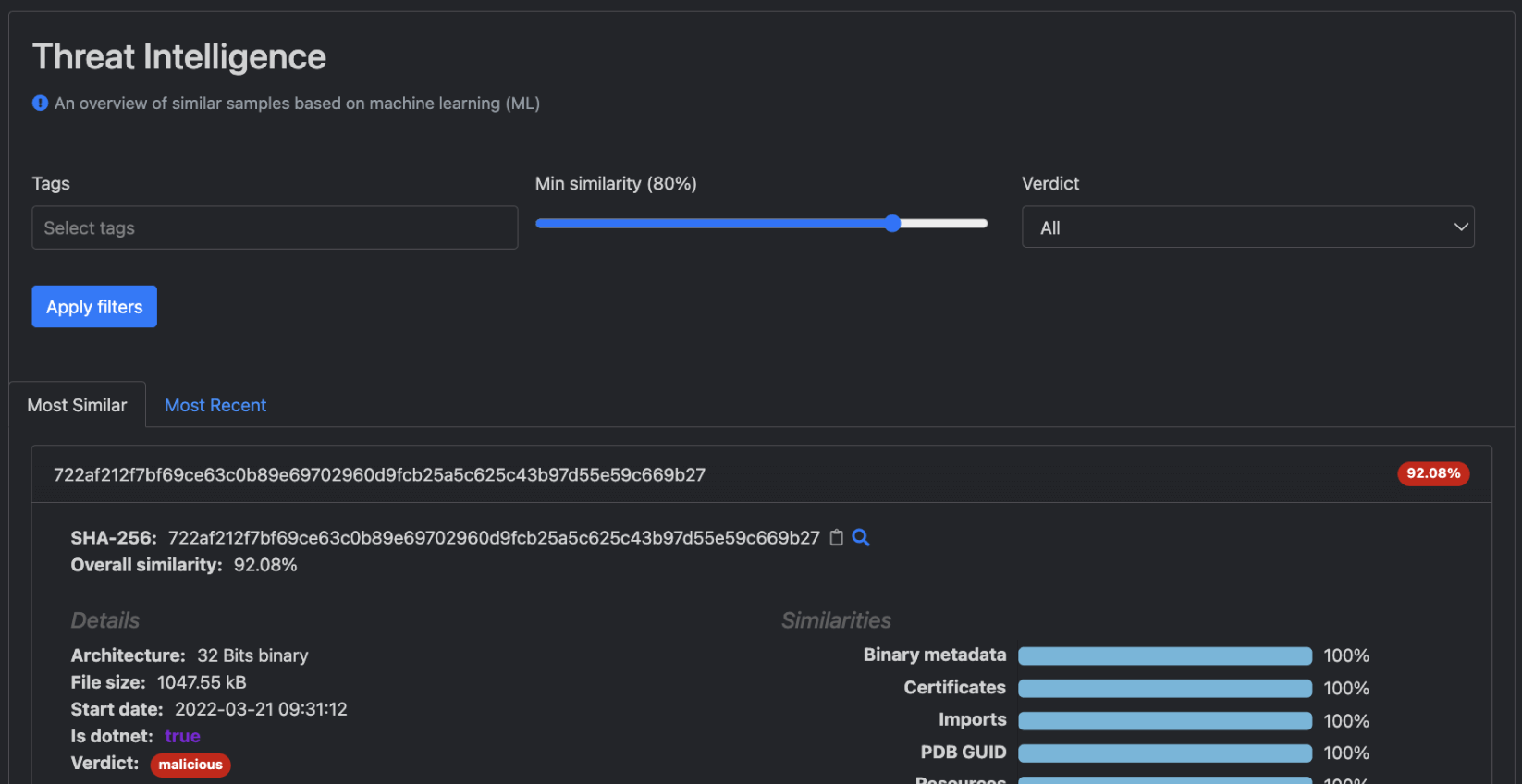
Threat Intelligence Subpage
The Threat Intelligence subpage offers users a variety of features, such as the ability to view the most closely related files and utilize the filterable user interface. By selecting a specific SHA256 identifier, users can obtain detailed information about the associated file’s similarity, along with its high-level details.
Key Use Cases
As with any machine learning application, it’s crucial to validate the results of a similarity search. However, this feature offers a wide range of possibilities for users to efficiently explore and identify relevant files. The indexing search provides an exceptionally fast hash search for all types of files, forming the cornerstone of the product. The following entities can benefit from the similarity search functionality.
- Cyber threat intelligence analysts, who can leverage this capability to investigate and detect new and evolving threats, improving their organization's security posture.
- Threat hunters, who can proactively search for indicators of compromise (IOCs) and potential vulnerabilities, thereby preempting malicious activities.
- Anyone who is interested in exploring relationships between files and identifying similarities, including researchers, investigators, and analysts.
Get access to Similarity Search
Discover how you can integrate similarity search into your processes by reading our documentation at https://www.opswat.com/docs. Please note that the similarity search feature is an add-on available exclusively to our paid Filescan or Threat Intel package users. If you're interested in exploring this feature, sign up for an account today!

